:bangbang: :new: NVIDIA H200 已经发布 & 并在 TensorRT-LLM 上进行了优化。在此了解更多关于 H200 以及 H100 比较的信息: H200 在 TensorRT-LLM 上使用 Llama2-13B 实现了接近 12,000 个 tokens/秒
H100 在 TensorRT-LLM 中性能是 A100 的 4.6 倍,在 100 毫秒内达到 10,000 tok/s 的首个 token#
在 Hopper 和 Ampere 上评估的 TensorRT-LLM 显示 H100 FP8 的最大吞吐量比 A100 高达 4.6 倍,并且首个 token 延迟快 4.4 倍。 H100 FP8 能够在 峰值吞吐量 下为 64 个并发请求实现超过 10,000 个输出 tok/s,同时保持 100 毫秒的首个 token 延迟。 对于 最小延迟 应用,TRT-LLM H100 可以实现小于 10 毫秒的首个 token 延迟。
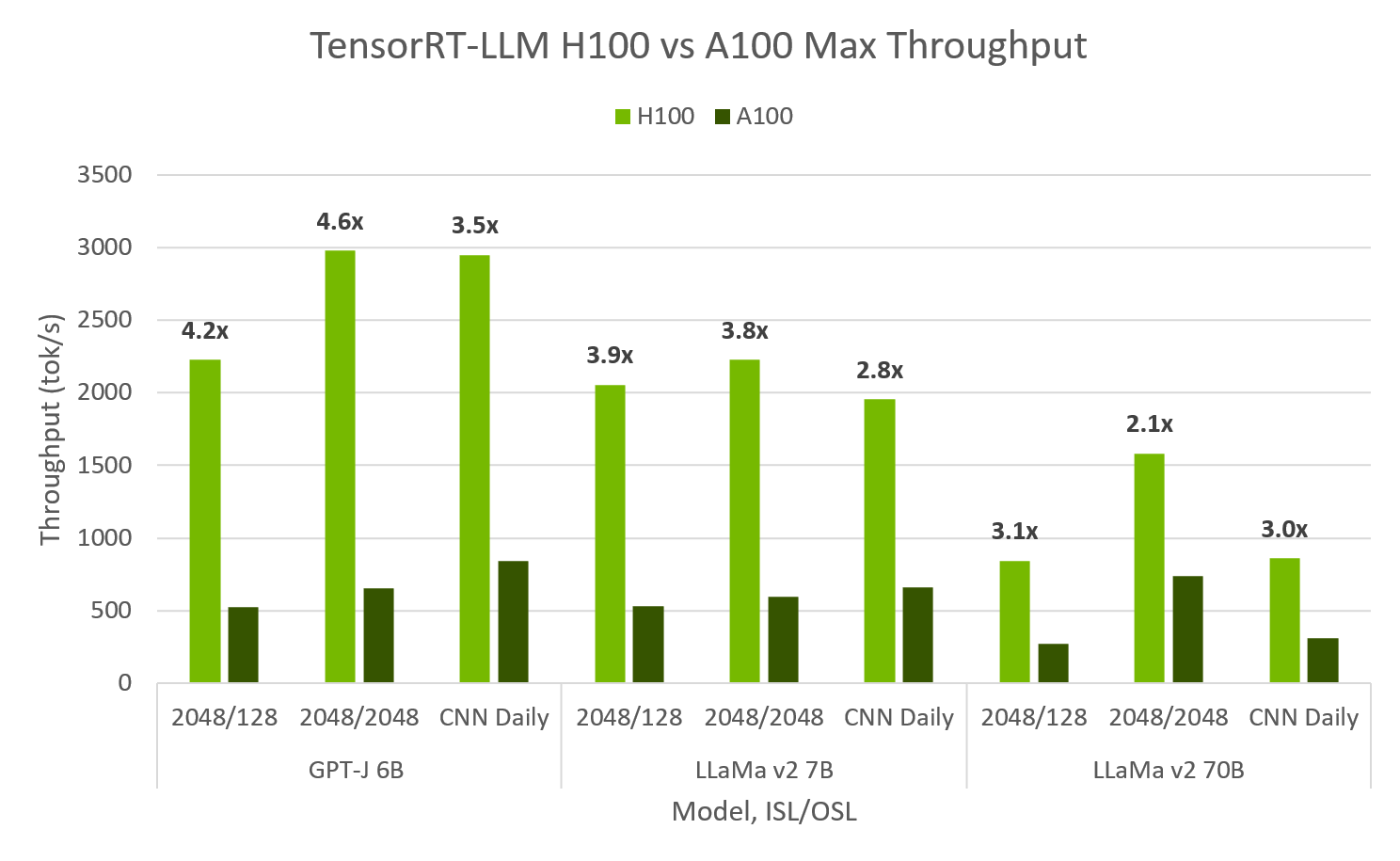
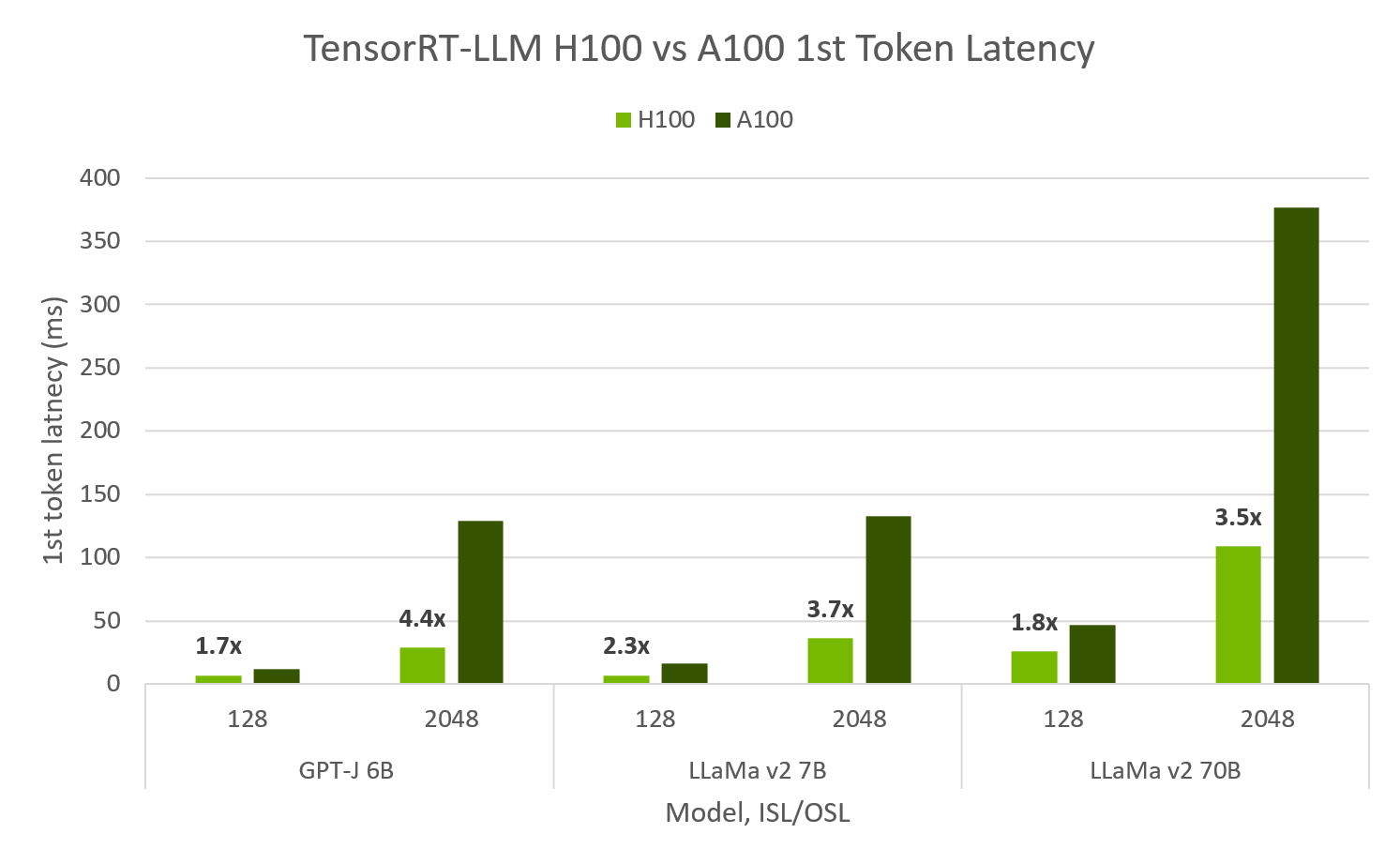
H100 和 A100 上的 TensorRT-LLM 吞吐量和首个 token 延迟。 H100 FP8, A100 FP16, SXM 80GB GPUs, ISL/OSL’s provided, TP=1, BS=32/64 最大吞吐量, BS=1 首个 token 延迟. TensorRT-LLM v0.5.0, TensorRT 9.1. 最大吞吐量通过扫描 BS 1,2,…,64 计算得出. 在最大的成功值处获取吞吐量。
最大吞吐量 & 最小延迟
模型 |
批大小 |
输入长度 |
输出长度 |
吞吐量(输出 tok/s) |
首个 Token 延迟 (ms) |
|---|---|---|---|---|---|
H100 |
|||||
GPT-J 6B |
64 |
128 |
128 |
10,907 |
102 |
GPT-J 6B |
1 |
128 |
- |
185 |
7.1 |
A100 |
|||||
GPT-J 6B |
64 |
128 |
128 |
3,679 |
481 |
GPT-J 6B |
1 |
128 |
- |
111 |
12.5 |
加速 |
|||||
GPT-J 6B |
64 |
128 |
128 |
3.0x |
4.7x |
GPT-J 6B |
1 |
128 |
- |
2.4x |
1.7x |
FP8 H100, FP16 A100, SXM 80GB GPUs, TP1, ISL/OSL’s provided, TensorRT-LLM v0.5.0., TensorRT 9.1
这些图表和表格背后的完整数据,包括具有更高 TP 值的更大的模型,可以在 TensorRT-LLM 的 性能文档 中找到
敬请关注即将推出的关于 Llama 的重点介绍!
基于 FP8 的 H100 上的 MLPerf#
在最新的 MLPerf 结果中,NVIDIA 证明了 NVIDIA H100 上的模型推理性能比 NVIDIA A100 Tensor Core GPU 上的先前结果提高了 4.5 倍。 使用相同的数据类型,H100 比 A100 提高了 2 倍。 切换到 FP8 导致速度再次提高 2 倍。
什么是 H100 FP8?#
H100 是 NVIDIA 的下一代、最高性能的数据中心 GPU。 H100 基于 NVIDIA Hopper GPU 架构,可加速云数据中心、服务器、边缘系统和工作站中的 AI 训练和推理、HPC 和数据分析应用程序。 H100 提供对 FP8 数据类型的原生支持,与 H100 上的 16 位浮点选项相比,可以使性能翻倍,内存消耗减半。
深度学习的 FP8 格式 论文中介绍的 FP8 规范可用于加速训练以及使用 16 位格式训练的模型的训练后量化。 该规范由两种编码组成 - E4M3(4 位指数和 3 位尾数)和 E5M2(5 位指数和 2 位尾数)。 推荐的 FP8 编码用途是 E4M3 用于权重和激活张量,E5M2 用于梯度张量。
在实践中,FP8 可以将 H100(FP8 与 FP16)的感知性能提高 2 倍以上。 FP8 是一种 W8A8 格式,这意味着权重以 8 位存储,激活或计算也是如此。 8 位权重会降低 GPU 内存消耗和带宽,这意味着可以将更大的模型、序列长度或批处理大小放入同一个 GPU 中。 这可以启用新的用例,更大的最大批处理大小可以将最大吞吐量提高到 FP16 H100 的 2 倍以上。