性能分析#
ScopedTimer#
wp.ScopedTimer 对象可以用于深入了解 Warp 应用程序的性能
@wp.kernel
def inc_loop(a: wp.array(dtype=float), num_iters: int):
i = wp.tid()
for j in range(num_iters):
a[i] += 1.0
n = 10_000_000
devices = wp.get_cuda_devices()
# pre-allocate host arrays for readback
host_arrays = [
wp.empty(n, dtype=float, device="cpu", pinned=True) for _ in devices
]
# code for profiling
with wp.ScopedTimer("Demo"):
for i, device in enumerate(devices):
a = wp.zeros(n, dtype=float, device=device)
wp.launch(inc_loop, dim=n, inputs=[a, 500], device=device)
wp.launch(inc_loop, dim=n, inputs=[a, 1000], device=device)
wp.launch(inc_loop, dim=n, inputs=[a, 1500], device=device)
wp.copy(host_arrays[i], a)
ScopedTimer 构造函数唯一必需的参数是一个字符串标签,用于在读取输出时区分多个定时代码段。上面的代码片段将打印类似这样的消息
Demo took 0.52 ms
默认情况下,ScopedTimer 测量 CPU 上的运行时间,并且不会引入任何 CUDA 同步。由于大多数 CUDA 操作是异步的,因此结果不包括在 CUDA 设备上执行内核和内存传输所花费的时间。但它仍然是一个有用的测量,因为它显示了在 CPU 上调度 CUDA 操作所花费的时间。
要获得包括设备执行时间在内的总时间,请使用 synchronize=True 标志创建 ScopedTimer。这等效于在定时代码段之前和之后调用 wp.synchronize()。在开始时进行同步可确保在启动计时器之前完成所有先前的 CUDA 工作。在结束时进行同步可确保在停止计时器之前完成所有定时工作。对于上面的示例,结果可能如下所示
Demo took 4.91 ms
计时值会因运行而略有不同,并且取决于系统硬件和当前负载。此处提供的示例结果是在具有一个 RTX 4090 GPU、一个 RTX 3090 GPU 和一个 AMD Ryzen Threadripper Pro 5965WX CPU 的系统上获得的。对于每个 GPU,该代码都会分配并初始化一个包含 1000 万个浮点元素的数组。然后,它会在数组上启动 inc_loop 内核三次。内核将每个数组元素递增给定的次数 - 500、1000 和 1500。最后,代码将数组内容复制到 CPU。
使用许多异步和并发操作分析复杂的程序可能很棘手。像 NVIDIA Nsight Systems 这样的分析工具可以以可视方式呈现结果,并捕获大量的计时信息以供深入研究。对于能够可视化 NVTX 范围的分析工具,可以使用 use_nvtx=True 参数创建 ScopedTimer。这将在时间线上标记 CPU 执行范围,以便于进行视觉检查。可以使用 color 参数自定义颜色,如下所示
with wp.ScopedTimer("Demo", use_nvtx=True, color="yellow"):
...
要使用 NVTX 集成,您需要安装 NVIDIA NVTX Python 包。
pip install nvtx
该软件包允许您将自定义 NVTX 范围插入到您的代码中 (nvtx.annotate) 并自定义 颜色。
这是演示代码在 Nsight Systems 中的外观(单击以放大图像)
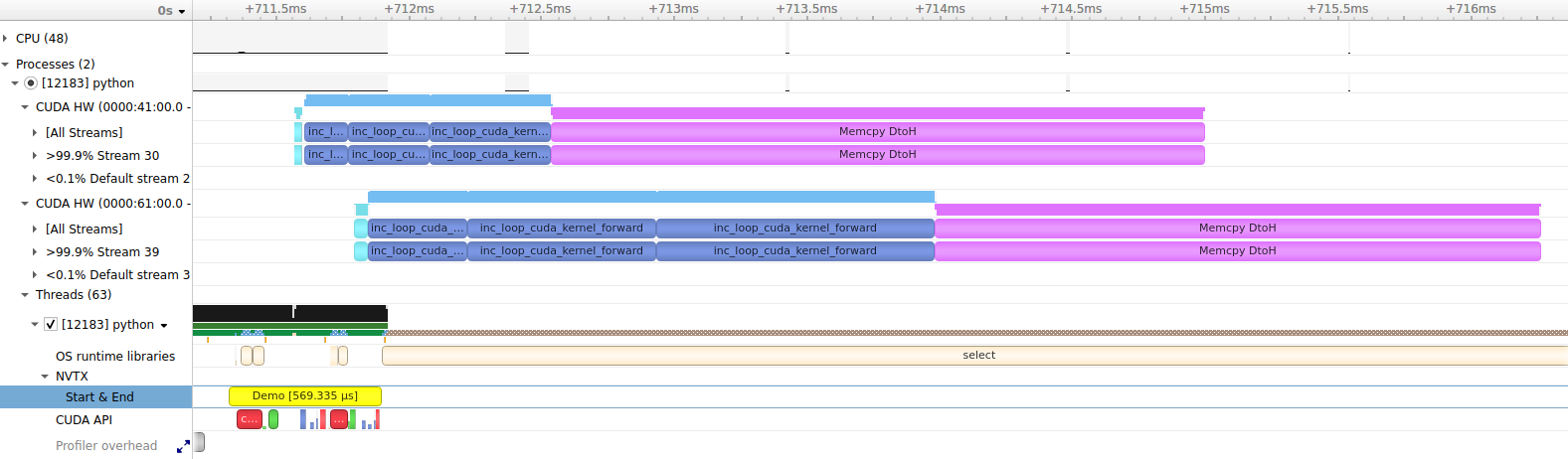
我们可以从该捕获中得出一些值得注意的观察结果。如 NVTX / Start & End 行所示,在 CPU 上调度和启动工作大约需要半毫秒。此时间还包括在两个 CUDA 设备上分配数组的时间。我们可以看到,每个设备上的执行相对于主机是异步的,因为 CUDA 操作在黄色 Demo NVTX 范围完成之前开始运行。我们还可以看到,不同 CUDA 设备上的操作并发执行,包括内核和内存传输。内核在第一个 CUDA 设备 (RTX 4090) 上运行速度比第二个设备 (RTX 3090) 快。内存传输在每个设备上花费的时间大致相同。使用固定的 CPU 数组作为传输目的地允许传输异步运行,而无需涉及 CPU。
请查看 并发文档,了解有关异步操作的更多信息。
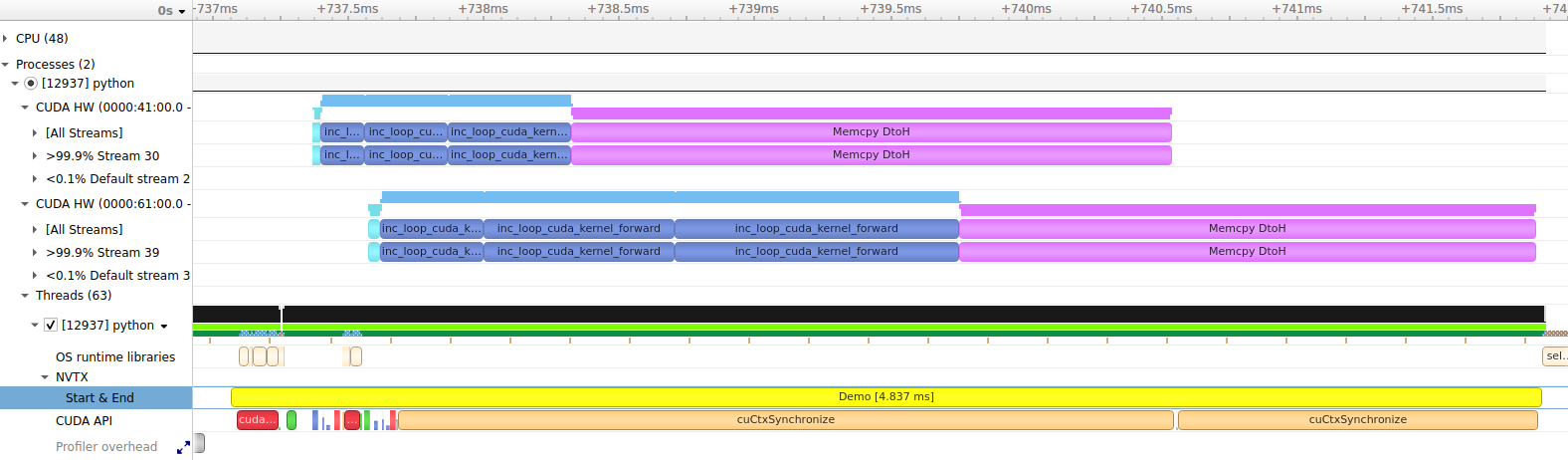
请注意,在此运行中未启用同步,因此 NVTX 范围仅跨越用于调度 CUDA 工作的 CPU 操作。启用同步后,计时器将等待所有 CUDA 工作完成,因此 NVTX 范围将跨越两个设备的同步
with wp.ScopedTimer("Demo", use_nvtx=True, color="yellow", synchronize=True):
...
CUDA 活动分析#
ScopedTimer 支持对单个 CUDA 活动(如内核和内存操作)进行计时。这是通过测量设备上 CUDA 事件 之间的时间来实现的。要获取有关 CUDA 活动的信息,请将 cuda_filter 参数传递给 ScopedTimer 构造函数。cuda_filter 可以是以下值的按位组合
|
Warp 内核(包括所有用 Python 编写为 |
|
内置内核(包括 Warp 库在底层使用的内核) |
|
CUDA 内存传输(主机到设备、设备到主机、设备到设备以及对等) |
|
CUDA memset 操作(例如,在 |
|
CUDA 图启动 |
|
为方便起见,结合了以上所有内容。 |
当指定非零 cuda_filter 时,Warp 将注入 CUDA 事件以进行计时,并在 ScopeTimer 完成时报告结果。这会给代码增加一些开销,因此应仅在分析期间使用。
CUDA 事件计时分辨率约为 0.5 微秒。短操作的报告执行时间可能比操作在设备上实际花费的时间长。这是由于计时分辨率和添加的检测代码的开销造成的。为了更精确地分析短操作,像 Nsight Systems 这样的工具可以报告更准确的数据。
可以使用以下方法启用 CUDA 分析和演示代码
with wp.ScopedTimer("Demo", cuda_filter=wp.TIMING_ALL):
...
这会将附加信息添加到输出
CUDA timeline:
----------------+---------+------------------------
Time | Device | Activity
----------------+---------+------------------------
0.021504 ms | cuda:0 | memset
0.163840 ms | cuda:0 | forward kernel inc_loop
0.306176 ms | cuda:0 | forward kernel inc_loop
0.451584 ms | cuda:0 | forward kernel inc_loop
2.455520 ms | cuda:0 | memcpy DtoH
0.051200 ms | cuda:1 | memset
0.374784 ms | cuda:1 | forward kernel inc_loop
0.707584 ms | cuda:1 | forward kernel inc_loop
1.042432 ms | cuda:1 | forward kernel inc_loop
2.136096 ms | cuda:1 | memcpy DtoH
CUDA activity summary:
----------------+---------+------------------------
Total time | Count | Activity
----------------+---------+------------------------
0.072704 ms | 2 | memset
3.046400 ms | 6 | forward kernel inc_loop
4.591616 ms | 2 | memcpy DtoH
CUDA device summary:
----------------+---------+------------------------
Total time | Count | Device
----------------+---------+------------------------
3.398624 ms | 5 | cuda:0
4.312096 ms | 5 | cuda:1
Demo took 0.92 ms
第一部分是 CUDA 时间线,其中列出了按问题顺序捕获的所有活动。我们看到设备 cuda:0 上的 memset,它对应于清除 wp.zeros() 中的内存。紧随其后的是在 cuda:0 上启动 inc_loop 内核三次,以及由 wp.copy() 触发的从设备到主机的内存传输。其余条目重复设备 cuda:1 上的类似操作。
下一部分是 CUDA 活动摘要,其中报告了每种活动类型所花费的累积时间。在此,memsets、内核启动和内存传输操作被分组在一起。这是查看总体上时间花费在何处的好方法。memsets 非常快。inc_loop 内核启动大约花费了三毫秒的组合 GPU 时间。内存传输花费的时间最长,超过四毫秒。
CUDA 设备摘要 显示了每个设备花费的总时间。我们看到设备 cuda:0 大约花费了 3.4 毫秒来完成任务,而设备 cuda:1 大约花费了 4.3 毫秒。该摘要可用于评估多 GPU 应用程序中的工作负载分配。
最后一行显示了 CPU 所花费的时间,与默认 ScopedTimer 选项相同(在本例中没有同步)。
自定义输出#
可以自定义活动计时结果的报告方式。默认使用函数 warp.timing_print()。要使用不同的报告函数,请将其作为 report_func 参数传递给 ScopedTimer。自定义报告函数应将 warp.TimingResult 对象列表作为第一个参数。列表中的每个结果对应于一个活动,该列表表示完整的记录时间线。通过手动遍历列表,您可以自定义输出的格式、应用自定义排序规则以及根据需要聚合结果。第二个参数是一个字符串缩进,应在每行的开头打印。这是为了与嵌套计时器使用的 ScopedTimer 缩进规则兼容。
这是一个自定义报告函数的示例,它聚合了在正向和反向内核中花费的总时间
def print_custom_report(results, indent=""):
forward_time = 0
backward_time = 0
for r in results:
# aggregate all forward kernels
if r.name.startswith("forward kernel"):
forward_time += r.elapsed
# aggregate all backward kernels
elif r.name.startswith("backward kernel"):
backward_time += r.elapsed
print(f"{indent}Forward kernels : {forward_time:.6f} ms")
print(f"{indent}Backward kernels : {backward_time:.6f} ms")
让我们将其应用于 Warp 示例之一
from warp.examples.optim.example_cloth_throw import Example
example = Example(None)
example.use_graph = False # disable graphs so we get timings for individual kernels
with wp.ScopedTimer("Example", cuda_filter=wp.TIMING_KERNEL, report_func=print_custom_report):
for iteration in range(5):
example.step()
这将生成如下报告
Forward kernels : 187.098367 ms
Backward kernels : 245.070177 ms
直接使用活动计时函数#
也可以完全不使用 ScopedTimer 来捕获活动计时。只需调用 warp.timing_begin() 开始记录活动计时,然后调用 warp.timing_end() 停止并获取记录的活动列表。您可以使用 warp.timing_print() 打印默认的活动报告,或者从结果列表中生成您自己的报告。
wp.timing_begin(cuda_filter=wp.TIMING_ALL)
...
results = wp.timing_end()
wp.timing_print(results)
局限性#
目前,详细的活动计时仅适用于 CUDA 设备,但将来可能会添加对 CPU 计时的支持。
活动分析仅记录使用 Warp API 启动的活动。它不会捕获其他框架启动的 CUDA 活动。可以使用像 Nsight Systems 这样的分析工具来检查整个程序的活动。
CUDA 事件计时#
CUDA 事件可用于 ScopedTimer 之外的计时目的。这是一个例子
with wp.ScopedDevice("cuda:0") as device:
# ensure the module is loaded
wp.load_module(device=device)
# create events with enabled timing
e1 = wp.Event(enable_timing=True)
e2 = wp.Event(enable_timing=True)
n = 10000000
# start timing...
wp.record_event(e1)
a = wp.zeros(n, dtype=float)
wp.launch(inc, dim=n, inputs=[a])
# ...end timing
wp.record_event(e2)
# get elapsed time between the two events
elapsed = wp.get_event_elapsed_time(e1, e2)
print(elapsed)
必须使用标志 enable_timing=True 创建事件。第一个事件记录在计时代码的开始处,第二个事件记录在结束处。函数 warp.get_event_elapsed_time() 用于计算两个事件之间的时间差。我们必须确保两个事件都已在设备上完成,然后才能调用 warp.get_event_elapsed_time()。默认情况下,此函数将使用 warp.synchronize_event() 在第二个事件上同步。如果不需要这样做,用户可以传递 synchronize=False 标志,并且必须使用其他方法来确保两个事件在调用该函数之前都已完成。
请注意,由于 CUDA 事件的计时分辨率和分析代码的开销,对非常短的操作进行计时可能会产生夸大的结果。在大多数情况下,使用 ScopedTimer 进行 CUDA 活动分析的开销会更小,精度更高。为了获得最准确的结果,应使用 NVIDIA Nsight Systems 等分析工具。使用手动事件计时 API 的主要好处是,它可以对代码的任意部分进行计时,而不是单个活动。
CUDA Graphs 中的计时#
使用 enable_timing=True 标志创建的事件可用于 CUDA 图形内部的计时。我们像往常一样在图形捕获期间记录事件,但在图形启动和同步之前,计时将不可用。
with wp.ScopedDevice("cuda:0") as device:
# ensure the module is loaded
wp.load_module(device=device)
# create events with enabled timing
e1 = wp.Event(enable_timing=True)
e2 = wp.Event(enable_timing=True)
n = 10000000
# begin graph capture
with wp.ScopedCapture() as capture:
# start timing...
wp.record_event(e1)
a = wp.zeros(n, dtype=float)
wp.launch(inc, dim=n, inputs=[a])
# ...end timing
wp.record_event(e2)
# launch the graph
wp.capture_launch(capture.graph)
# get elapsed time between the two events during the launch
elapsed = wp.get_event_elapsed_time(e1, e2)
print(elapsed)
Nsight Compute 分析#
虽然 Nsight Systems 提供了应用程序的软件和硬件活动的系统范围的可视化,但 Nsight Compute 可用于详细的 CUDA 内核性能分析。一个可能的工作流程周期可能包括以下步骤
使用 Nsight Systems 识别最耗时的内核。
使用 Nsight Compute 仅分析前一步中识别的内核的几次执行,以获得优化操作的详细建议。
通过重复该周期来重新检查整体性能。
在使用 Nsight Compute 分析内核之前,重要的是包含感兴趣内核的模块应使用行信息进行编译。可以通过使用 warp.config.lineinfo 设置在全局级别进行设置,或者使用 lineinfo 标志在每个模块的基础上进行设置(参见 模块设置),例如 wp.set_module_options({"lineinfo": True})。这允许 Nsight Compute 将汇编 (SASS) 与高级 Python 或 CUDA-C 代码相关联,但代价是内核缓存中的文件更大(大约是没有行信息的文件大小的两倍)。
可能需要提升的应用程序权限才能访问必要的硬件计数器,以便使用 Nsight Compute 分析内核 (说明)
Nsight Compute 可以作为交互式分析器和命令行分析器运行。命令行分析器可以将报告存储在一个文件中,该文件稍后可以使用 UI 可执行文件 (ncu-ui) 打开。
源代码关联选项#
默认情况下,Warp 在 CUDA-C 代码中发出行指令,这有助于将 SASS 指令与生成它的 Python Warp 内核或函数代码相关联。这有时会使 Nsight Compute 中数据的分析变得复杂,因为一行 Python 代码可能与数十甚至数百个 SASS 指令相关联。有时,通过将 warp.config.line_directives 设置为 False,将 SASS 指令直接与内核缓存中的 CUDA-C 源代码相关联可能很有用。CUDA-C 代码中的注释指示生成它的 Python 代码。
示例:分析来自 example_sph.py 的内核#
首先,我们需要修改 示例 以使用行信息进行编译。
import numpy as np
import warp as wp
import warp.render
wp.config.lineinfo = True
我们决定分析模拟的前 10 帧,而不是在 Nsight Systems 中分析整个示例,并且跳过将粒子位置写入 USD 文件,以便我们可以专注于与 GPU 相关的优化
nsys profile --stats=true python example_sph.py --stage_path None --num_frames 10
输出告诉我们 get_acceleration 和 compute_density 内核占据了 GPU 上的大部分时间。我们还从输出中看到它们的完整名称变为 get_acceleration_a9fb4286_cuda_kernel_forward 和 compute_density_99e58138_cuda_kernel_forward,但确切的名称可能因不同的系统和 Warp 版本而异。
接下来,我们使用 Nsight Compute 分析内核。让我们首先关注 get_acceleration 内核。使用命令行分析器将报告保存到 example_sph.ncu-rep 的基本命令是
ncu -o example_sph -k get_acceleration_a9fb4286_cuda_kernel_forward --set full python example_sph.py --stage_path None --num_frames 10
此命令的执行时间比 Nsight Systems 命令长得多,因为 Nsight Compute 对每个内核启动执行多次传递以收集不同的指标。为了加快分析速度,我们可以使用 -c [ --launch-count ] arg 选项来限制收集的分析结果的数量
ncu -o example_sph -k get_acceleration_a9fb4286_cuda_kernel_forward --set full -c 5 python example_sph.py --stage_path None --num_frames 10
此外,我们可以添加 -f 选项来覆盖输出文件,并添加 --open-in-ui 以在 UI 中自动打开报告
ncu --open-in-ui -f -o example_sph -k get_acceleration_a9fb4286_cuda_kernel_forward --set full -c 5 python example_sph.py --stage_path None --num_frames 10
以下屏幕截图显示了 Nsight Compute 报告中的 Python/SASS 关联视图(单击以放大)
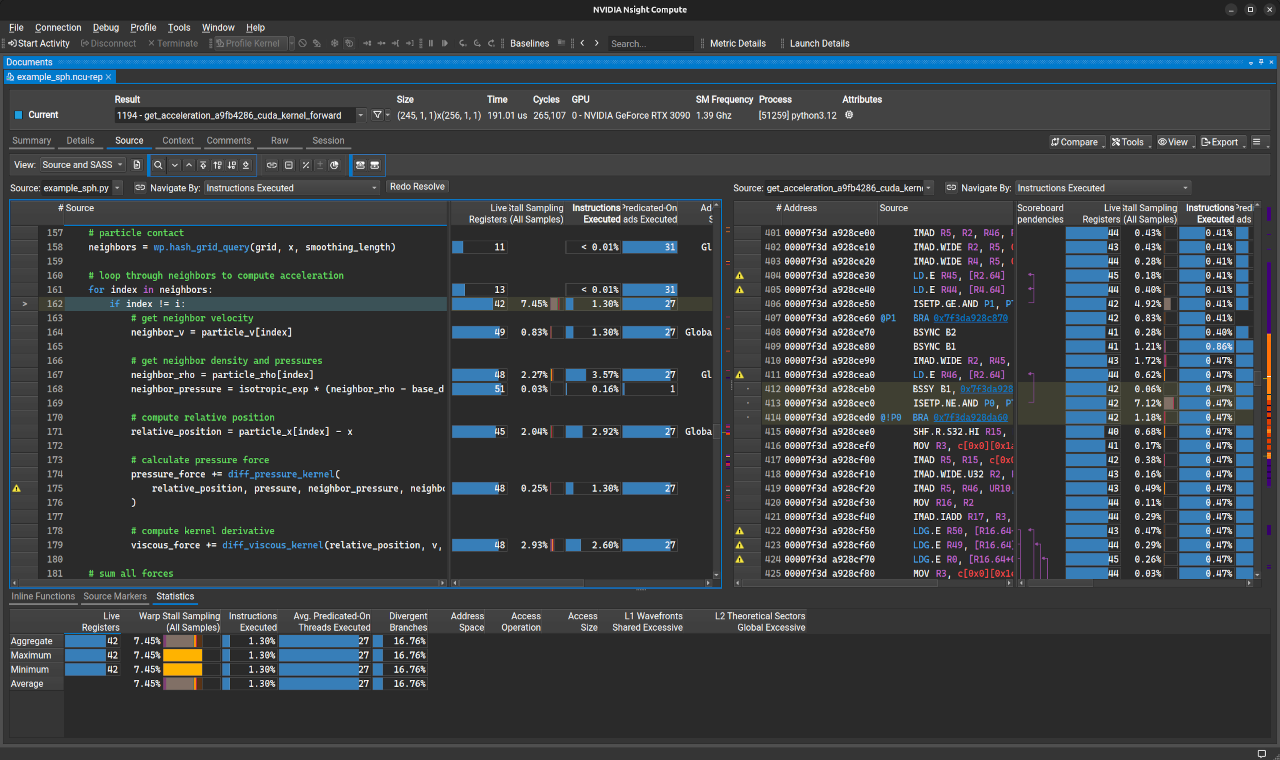
有关如何在 UI 中导航报告的更多信息,请查阅 Nsight Compute 用户指南。如果 源代码比较 窗口仅显示低级 SASS 代码,则可能是模块没有使用行信息进行编译。
我们可以通过更改命令中的内核名称为 compute_density_99e58138_cuda_kernel_forward,以类似的方式分析 compute_density 内核。
分析应用程序中的所有内核#
在前面的例子中,我们使用了 -k 选项,根据 Nsight Systems 的分析,有选择地分析了最耗时的内核。如果我们只是想分析应用程序中前 20 个内核的启动,我们可以去掉 -k 选项,并将 -c 选项的值增加到 20。
ncu --open-in-ui -f -o example_sph --set full -c 20 python example_sph.py --stage_path None --num_frames 10
在 Nsight Compute 报告中保留源代码上下文#
使用 ncu 时,使用 -import-source 1 选项将 Python 或 CUDA-C 源代码文件永久导入到报告中非常方便,例如:
ncu --open-in-ui --import-source 1 -f -o example_sph -k get_acceleration_a9fb4286_cuda_kernel_forward --set full -c 5 python example_sph.py --stage_path None --num_frames 10
这确保了在创建分析报告时拍摄了源文件的快照,从而防止了后续的源代码修改影响 SASS/源代码关联信息。例如,在运行分析命令后,在 example_sph.py 的顶部添加一个单行注释行,如果源文件没有导入到报告中,则会导致 Nsight Compute 中的 Python/SASS 关联不正确一行。
当分析命令不是从与源文件相同的目录运行时,还需要使用 --source-folders arg 选项来告诉 Nsight Compute 在哪些目录中搜索要导入到报告中的源文件。当使用 CUDA-C/SASS 相关性进行分析时(warp.config.line_directives 设置为 False)通常如此,除非 warp.config.kernel_cache_dir 已设置为当前工作目录。以下是一个分析命令示例,该命令指示 Nsight Compute 在 Linux 上的内核缓存目录中搜索源文件:
ncu --open-in-ui --import-source 1 --source-folders ~/.cache/warp/ -f -o example_sph -k get_acceleration_a9fb4286_cuda_kernel_forward --set full -c 5 python example_sph.py --stage_path None --num_frames 10
由于类似的原因,有时可能需要使用 warp.clear_kernel_cache() 清除内核缓存,以强制更新添加到 CUDA-C 代码中的 #line 指令。这是因为 Python 源文件的更改可能不会影响模块哈希,但会使行关联信息不正确。
分析 API 参考#
- class warp.ScopedTimer(
- name,
- active=True,
- print=True,
- detailed=False,
- dict=None,
- use_nvtx=False,
- color='rapids',
- synchronize=False,
- cuda_filter=0,
- report_func=None,
- skip_tape=False,
- 参数:
- indent = -1#
- enabled = True#
- __init__(
- name,
- active=True,
- print=True,
- detailed=False,
- dict=None,
- use_nvtx=False,
- color='rapids',
- synchronize=False,
- cuda_filter=0,
- report_func=None,
- skip_tape=False,
计时器的上下文管理器对象
- 参数:
name (str) – 计时器名称
active (bool) – 启用此计时器
print (bool) – 在上下文管理器退出时,将经过的时间打印到
sys.stdoutdetailed (bool) – 使用 cProfile 收集额外的分析数据,并在上下文退出时调用
print_stats()dict (Dict[str, List[float]] | None) – 列表的字典,经过的时间将使用
name作为键附加到该字典use_nvtx (bool) – 如果为 true,则计时功能将替换为 NVTX 范围
color (int | str) – 与 NVTX 范围关联的 ARGB 值(例如 0x00FFFF)或颜色名称(例如“cyan”)
synchronize (bool) – 将 CPU 线程与任何未完成的 CUDA 工作同步,以返回准确的 GPU 计时
cuda_filter (int) – CUDA 活动计时的过滤标志,例如
warp.TIMING_KERNEL或warp.TIMING_ALLreport_func (Callable[[List[TimingResult], str], None] | None) – 用于打印活动报告的回调函数。如果为
None,则将使用wp.timing_print()。skip_tape (bool) – 如果为 true,则计时器将不会记录在 tape 中
- timing_results#
活动计时结果列表,如果使用
cuda_filter请求收集- 类型:
List[TimingResult]
- warp.timing_end(synchronize=True)[source]#
结束详细的活动计时。
- 参数:
synchronize (bool) – 是否在计时结束前同步所有 CUDA 设备
- 返回:
所有记录的活动的
TimingResult对象列表。- 返回类型:
- warp.timing_print(results, indent='')[source]#
打印计时结果。
- 参数:
results (List[TimingResult]) – 要打印的
TimingResult对象列表。indent (str) – 可选的缩进,添加到所有输出行的前面。
- 返回类型:
None