安全指南#
允许 LLM 访问外部资源(例如搜索界面、数据库或 Wolfram Alpha 等计算资源)可以极大地提升其能力。然而,LLM 生成完成内容的不可预测性意味着,如果集成不慎,这些外部资源可能被攻击者操纵,从而显著增加部署这些组合模型的风险。
本文档阐述了安全地向 LLM 提供外部数据和计算资源访问权限的指南和原则。
黄金法则#
应当认为 LLM 在效果上是完全受用户控制的网页浏览器,并且其生成的所有内容都是不可信的。调用的任何服务必须在 LLM 用户的上下文中调用。在设计资源与 LLM 之间的内部 API(见下文)时,请自问“我会故意将带有此接口的资源直接暴露给互联网吗?”如果答案是“否”,您应该重新考虑您的集成方式。
假定的交互模型#
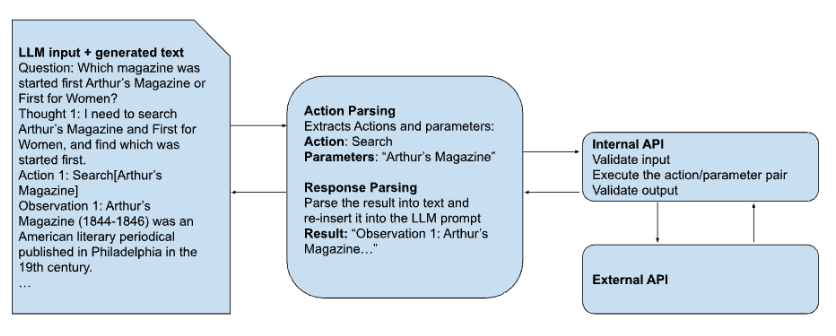
我们假定访问外部资源的数据流包含以下逻辑组件:
LLM,它接收提示作为输入并生成文本作为输出。
一个解析/分派引擎,它检查 LLM 输出,以判断是否需要调用外部资源。它负责以下任务:
识别必须调用一个或多个外部资源
识别请求的特定资源并提取包含在外部调用中的参数
使用正确的参数调用与请求资源相关的内部 API,包括与 LLM 用户关联的任何身份验证和/或授权信息
接收响应
将响应以正确的格式重新插入到 LLM 提示中的正确位置,并将其返回给管理 LLM 的进程以进行下一次 LLM 执行
一个内部 API,充当解析/分派引擎与单个外部资源之间的网关。这些 API 应尽可能使用硬编码的 URL、端点、路径等,旨在最小化攻击面。它负责以下任务:
验证当前通过身份验证的 LLM 用户是否被授权使用请求的参数调用请求的外部资源
验证输入
与外部资源交互并接收响应,包括任何身份验证
验证响应
将响应返回给分派引擎
解析步骤可以采取多种形式,包括预先向 LLM 加载令牌或动词以指示特定操作,或对输出行进行某种形式的嵌入搜索。目前常见的做法是包含一个特定的动词(例如,“FINISH”)来指示 LLM 应将结果返回给用户——实际上也将用户交互视为外部资源——然而,这个领域非常新,尚无“标准实践”可言。
我们将内部 API 与解析/分派引擎分离是出于以下原因:
使验证和授权代码与相关的 API 或服务共存
使外部 API 所需的任何身份验证信息与 LLM 隔离(以防止泄露)
促进 LLM 使用的外部资源的模块化开发,并减少外部 API 更改的影响。
具体指南#
优雅且秘密地失败 - 不要泄露服务详情#
当因任何原因(包括请求格式错误或授权不足)无法访问资源时,内部 API 应返回一个 LLM 可以适当响应的消息。应捕获并重写来自外部 API 的错误消息。返回给解析引擎的文本响应不应指示调用了哪个外部 API 或其失败原因。解析引擎应负责处理因缺乏授权导致的失败,并重建 LLM 生成内容,就像没有尝试调用该资源一样;对于其他非授权相关的失败,应返回一个不具体的失败消息,不透露集成的具体细节。
应当假设服务用户会尝试发现其特定提示或 LLM 会话未启用且他们无权使用的内部 API 和/或动词;用户不应该能通过与 LLM 的交互来检测某个内部 API 是否存在。
记录所有交互#
至少应记录以下信息:
触发解析/分派引擎动作的文本
该文本如何被解析为内部 API 调用以及参数是什么
提供给内部 API 的授权信息(包括:身份验证/授权的方法和时间、过期或持续时间、范围/角色信息、用户名或 UUID 等)
从内部 API 向外部 API 发起的调用以及结果
生成的文本如何被重新插入到 LLM 提示中
参数化并验证所有输入和输出#
任何对外部服务的请求都应参数化并有严格的验证要求。这些参数应注入到经过审计的模板中,并对照已验证的外部 API 版本进行匹配,同时将用户控制限制在最小的可行参数集内。应特别注意潜在的代码注入途径(例如 SQL 注入;Python 注释字符注入;搜索查询中的开放重定向等)以及响应中远程文件(或数据)包含的风险。在可能的情况下,还应对从外部 API 返回的值对照预期内容和格式进行验证,以防止注入或意外行为。
除了上述验证要求外,在将所有输出返回给解析/分派引擎之前,应检查是否存在私人信息,特别是泄露的 API 密钥、用户信息、API 信息等。反映用户信息(如用户身份验证、IP 地址、LLM 访问资源的上下文等)的 API 都可能是一个持续存在的难题,必须主动设计以应对。
尽可能避免持久化更改#
LLM 对外部 API 的请求应避免产生持久的状态更改,除非服务功能要求如此。执行高风险操作,例如:创建或删除表;下载文件;将任意文件写入磁盘;建立并后台运行进程;除非有特定要求,否则应明确禁止所有这些操作。在这种情况下,内部 API 应与一个内部服务角色相关联,该角色隔离进行和持久化这些更改的能力。在可能的情况下,考虑其他使用模式,这些模式无需 LLM 外部服务直接执行即可达到相同的效果(例如,提供一个指向预填的预约表单的链接,用户可以在提交前修改)。
所有持久性更改应通过参数化接口进行#
当外部 API 的主要功能是记录某些持久状态(例如,安排预约)时,这些更新应完全参数化并经过严格验证。此类 API 记录的任何信息都应与请求用户关联,并且应仔细评估和控制任何用户检索该信息(无论是为自己还是其他用户)的能力。
首选白名单和关闭失败模式#
在可能的情况下,任何外部接口应默认为拒绝请求,并将特定的允许请求和操作放在白名单上。
将所有身份验证信息与 LLM 隔离#
LLM 不应有权访问外部资源的任何身份验证信息;任何密钥、密码、安全令牌等应仅能被调用外部资源的内部 API 服务访问。调用服务还应负责验证用户访问相关资源的授权,这可以通过内部授权检查或与外部服务交互来完成。如上所述,所有关于任何错误、授权失败等信息都应从文本输出中移除并返回给解析服务。
主动与安全团队合作评估接口#
将 LLM 与外部资源集成本质上是 API 安全的一个实践。在设计这些接口时,尽早及时地与安全专家合作可以降低与这些接口相关的风险并加快开发速度。
就像网络服务器一样,进行红队测试和网络规模的测试是迈向工业级解决方案的必要条件。以零成本和最低 API 密钥注册摩擦的方式暴露 API,对于锻炼系统的规模、鲁棒性和内容审核能力至关重要。
对抗性测试#
AI 安全是社区共同努力的结果,这也是我们将 NeMo Guardrails 发布给社区的主要原因之一。我们希望汇聚众多开发者和爱好者,共同为可信赖的 AI 构建更好的解决方案。我们的首次发布是一个起点。我们构建了一系列护栏和教育示例,提供了有用的控制措施并能抵抗各种常见攻击,然而,它们并非完美无缺。我们已经对这些示例机器人进行了对抗性测试,并将很快发布一份关于更大规模研究的白皮书。以下是在创建您自己的机器人时需要注意的一些事项:
过度积极的内容审核:一些 AI 安全护栏有时可能会阻止原本安全的请求。当同时使用多个护栏时,这种情况更有可能发生。解决此问题的一种可能策略是在流程中使用逻辑来减少不必要的调用;例如,仅对事实性问题调用事实检查。
规范形式的过度泛化:NeMo Guardrails 使用像
ask about jobs report这样的规范形式来指导其行为,并泛化到 Colang 配置中未明确定义的情况。它有时可能会错误地进行泛化,导致护栏遗漏某些示例或意外触发。如果发生这种情况,通常可以通过在 Colang 文件中添加或调整define user形式,或修改配置中的示例对话来改进。非确定性:LLM 使用一种称为温度的概念以及其他技术来引入响应中的变异。这创造了更自然的体验,但有时可能在 LLM 应用程序中产生难以重现的意外行为。与所有 AI 应用程序一样,进行全面的评估和回归测试是良好的实践。
结论#
将外部资源集成到 LLM 中可以极大地提升其能力,并使其对最终用户更具价值。然而,表达能力的任何提升都伴随着潜在风险的增加。为了避免潜在的灾难性风险,包括未经授权的信息泄露以及远程代码执行,必须从安全第一的视角仔细周全地设计允许 LLM 访问这些外部资源的接口。