Minkowski Engine¶
![]()

Minkowski Engine 是一个用于稀疏张量的自动微分库。它支持所有标准的神经网络层,例如用于稀疏张量的卷积、池化、反池化和广播操作。有关更多信息,请访问文档页面。
新闻¶
2021-04-08 由于 pytorch 1.8 + CUDA 11 中的最新错误,建议使用 anaconda 进行安装。
2020-12-24 v0.5 现已推出!新版本为所有坐标管理功能提供 CUDA 加速。
示例网络¶
Minkowski Engine 支持可以在稀疏张量上构建的各种函数。我们在此列出一些流行的网络架构和应用程序。要运行示例,请安装软件包并在软件包根目录中运行该命令。
| 示例 | 网络和命令 |
|---|---|
| 语义分割 |   python -m examples.indoor |
| 分类 | 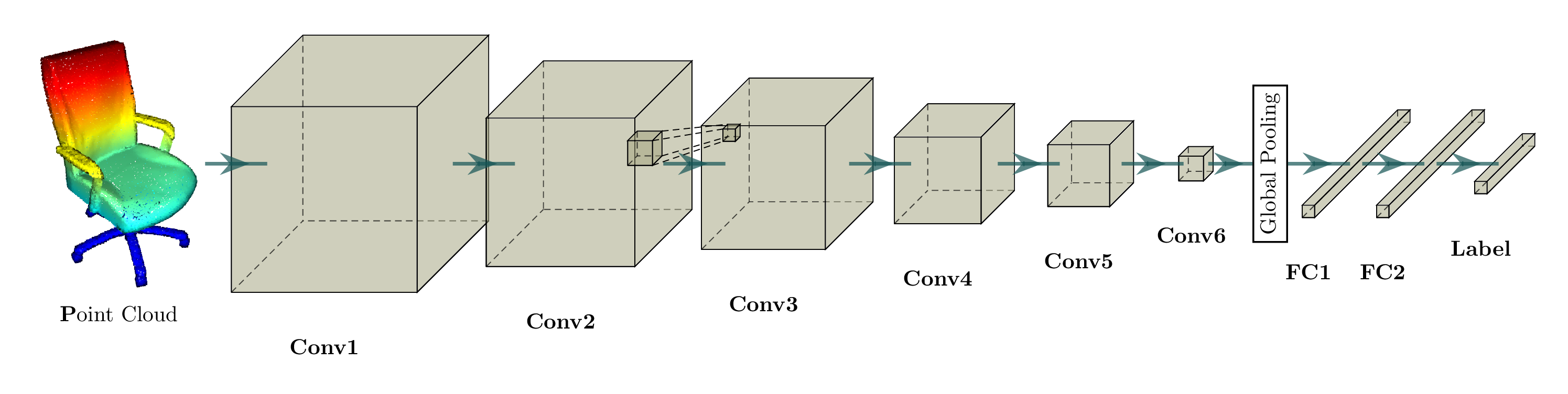 python -m examples.classification_modelnet40 |
| 重建 |   python -m examples.reconstruction |
| 补全 |  python -m examples.completion |
| 检测 | 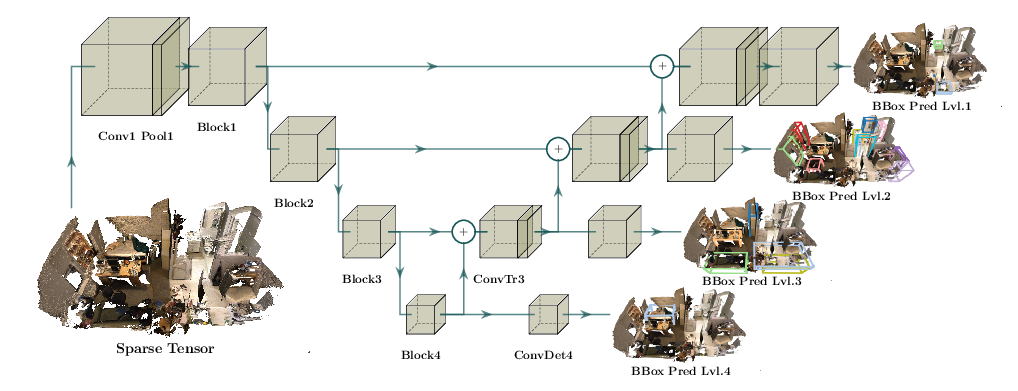 |
稀疏张量网络:用于空间稀疏张量的神经网络¶
压缩神经网络以加速推理并最大限度地减少内存占用已被广泛研究。模型压缩的流行技术之一是修剪卷积网络中的权重,也称为稀疏卷积网络。用于模型压缩的这种参数空间稀疏性压缩在密集张量上运行的网络,并且这些网络的所有中间激活也是密集张量。
但是,在这项工作中,我们专注于空间稀疏数据,特别是空间稀疏高维输入和 3D 数据以及 3D 对象表面的卷积,首先在 Siggraph’17 中提出。我们还可以将这些数据表示为稀疏张量,并且这些稀疏张量在高维问题中很常见,例如 3D 感知、配准和统计数据。我们将专门用于这些输入的神经网络定义为稀疏张量网络,并且这些稀疏张量网络处理并生成稀疏张量作为输出。为了构建稀疏张量网络,我们构建所有标准的神经网络层,例如 MLP、非线性、卷积、归一化、池化操作,就像我们在密集张量上定义它们的方式一样,并在 Minkowski Engine 中实现。
我们可视化了稀疏张量网络在稀疏张量上的操作,即卷积,如下所示。稀疏张量上的卷积层的工作方式与密集张量上的卷积层类似。但是,在稀疏张量上,我们在一些指定的点上计算卷积输出,我们可以在广义卷积中控制这些点。有关更多信息,请访问关于稀疏张量网络的文档页面和术语页面。
| 密集张量 | 稀疏张量 |
|---|---|
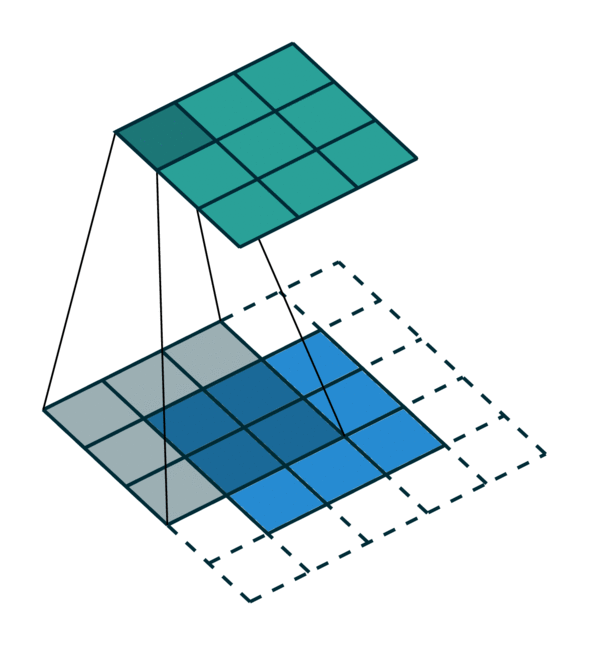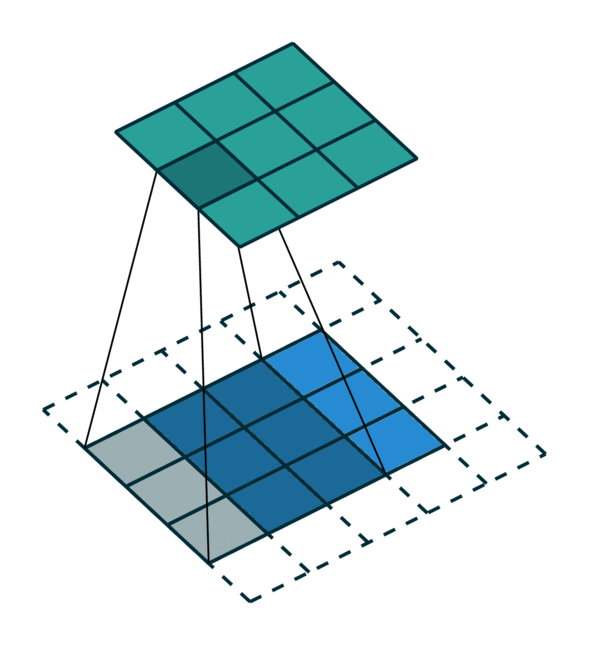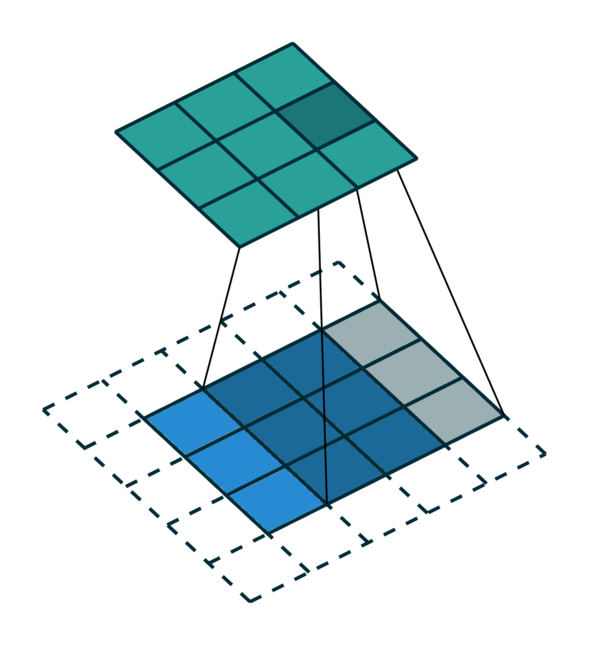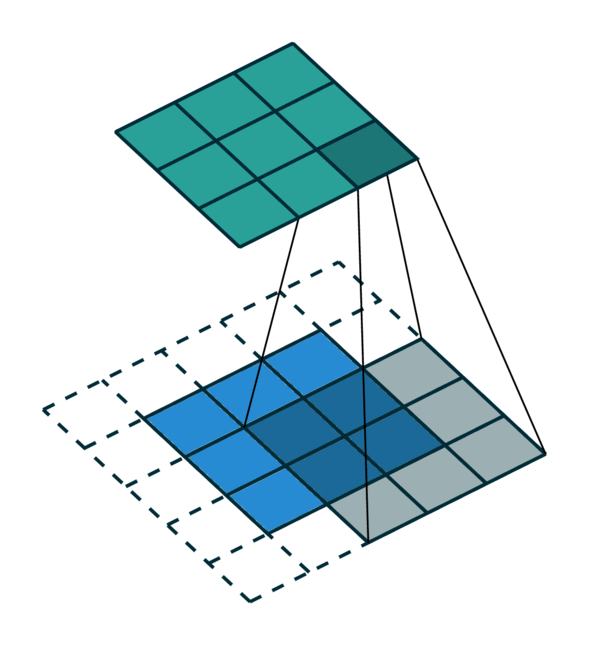 |
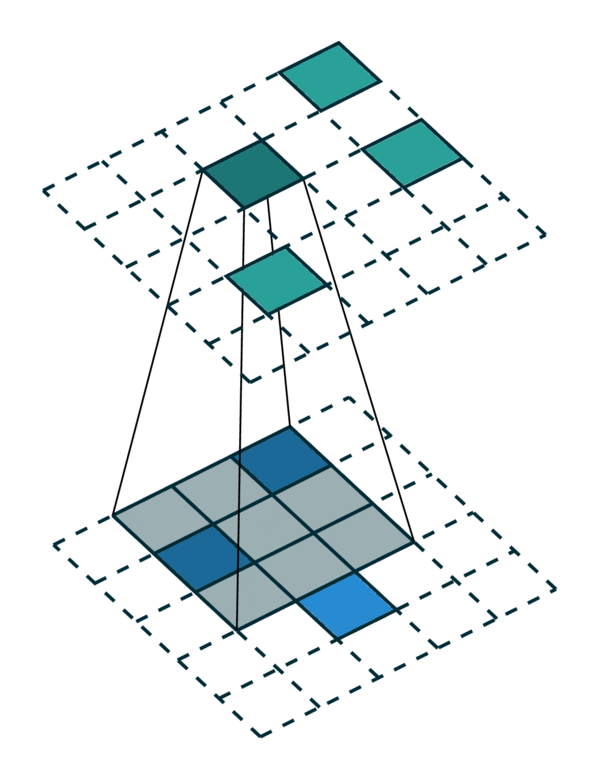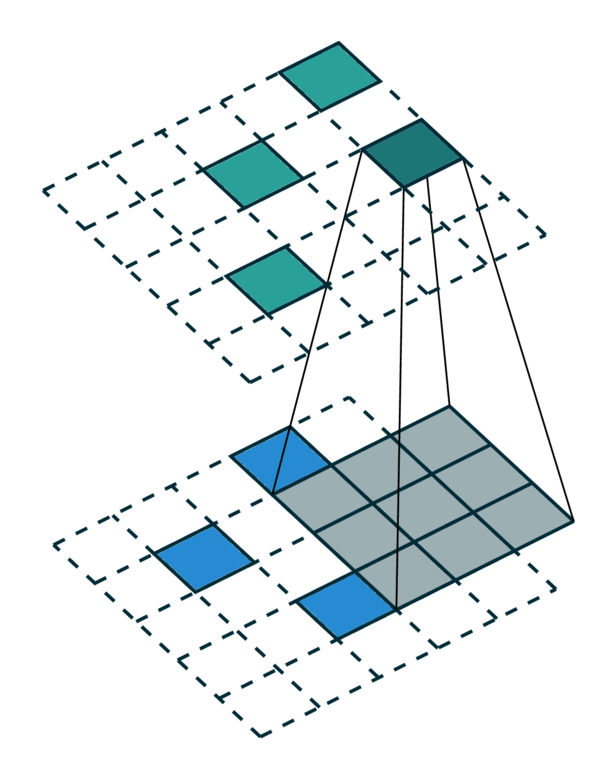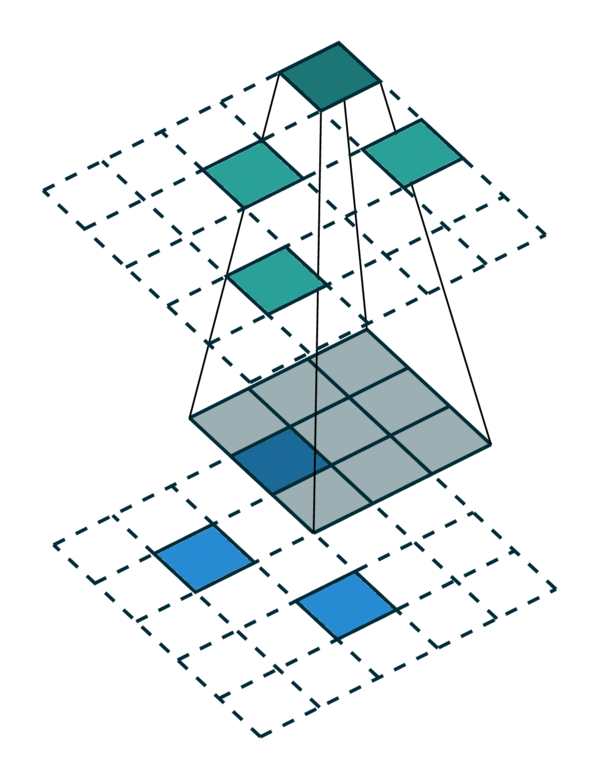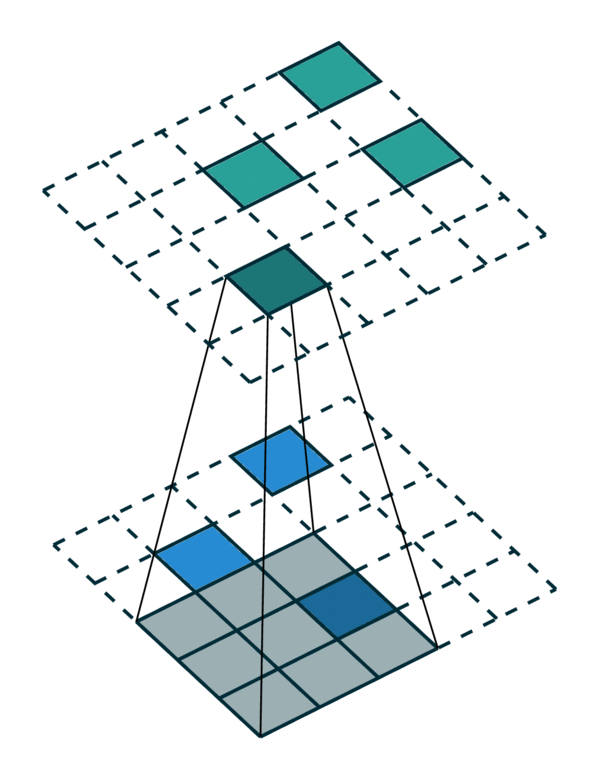 |
特性¶
无限的高维稀疏张量支持
所有标准的神经网络层(卷积、池化、广播等)
动态计算图
自定义内核形状
多 GPU 训练
多线程内核映射
多线程编译
高度优化的 GPU 内核
要求¶
Ubuntu >= 14.04
CUDA >= 10.1.243 和用于 pytorch 的相同 CUDA 版本(例如,如果您使用 conda cudatoolkit=11.1,则 MinkowskiEngine 编译使用 CUDA=11.1)
pytorch >= 1.7 (pytorch 1.8.1 + CUDA 11.X 不稳定。要指定 CUDA 版本,请使用 conda 进行安装。
conda install -y -c conda-forge -c pytorch pytorch=1.8.1 cudatoolkit=10.2)python >= 3.6
ninja(用于安装)
GCC >= 7.4.0
安装¶
您可以使用 pip、anaconda 或直接在系统上安装 Minkowski Engine。如果您在安装软件包时遇到问题,请查看安装 wiki 页面。如果找不到相关问题,请在github 问题页面上报告该问题。
Pip¶
MinkowskiEngine 通过 PyPI MinkowskiEngine 分发,可以使用 pip 简单地安装。首先,按照说明安装 pytorch。接下来,安装 openblas。
sudo apt install build-essential python3-dev libopenblas-dev
pip install torch ninja
pip install -U MinkowskiEngine --install-option="--blas=openblas" -v --no-deps
# For pip installation from the latest source
# pip install -U git+https://github.com/NVIDIA/MinkowskiEngine --no-deps
如果要为 setup 脚本指定参数,请参考以下命令。
# Uncomment some options if things don't work
# export CXX=c++; # set this if you want to use a different C++ compiler
# export CUDA_HOME=/usr/local/cuda-11.1; # or select the correct cuda version on your system.
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps \
# \ # uncomment the following line if you want to force cuda installation
# --install-option="--force_cuda" \
# \ # uncomment the following line if you want to force no cuda installation. force_cuda supercedes cpu_only
# --install-option="--cpu_only" \
# \ # uncomment the following line to override to openblas, atlas, mkl, blas
# --install-option="--blas=openblas" \
Anaconda¶
由于pytorch 中的错误,pytorch 1.8.1 只能与 CUDA 10.2 一起使用。要使用 CUDA 11.1,请改用 pytorch 1.7.1。
CUDA 10.2¶
我们建议安装 python>=3.6。首先,按照anaconda 文档在您的计算机上安装 anaconda。
sudo apt install g++-7 # For CUDA 10.2, must use GCC < 8
# Make sure `g++-7 --version` is at least 7.4.0
conda create -n py3-mink python=3.8
conda activate py3-mink
conda install openblas-devel -c anaconda
conda install pytorch=1.8.1 torchvision cudatoolkit=10.2 -c pytorch -c conda-forge
# Install MinkowskiEngine
export CXX=g++-7
# Uncomment the following line to specify the cuda home. Make sure `$CUDA_HOME/nvcc --version` is 10.2
# export CUDA_HOME=/usr/local/cuda-10.2
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=${CONDA_PREFIX}/include" --install-option="--blas=openblas"
# Or if you want local MinkowskiEngine
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
export CXX=g++-7
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
CUDA 11.X¶
我们建议安装 python>=3.6。首先,按照anaconda 文档在您的计算机上安装 anaconda。
conda create -n py3-mink python=3.8
conda activate py3-mink
conda install openblas-devel -c anaconda
conda install pytorch=1.7.1 torchvision cudatoolkit=11.0 -c pytorch -c conda-forge
# Install MinkowskiEngine
# Uncomment the following line to specify the cuda home. Make sure `$CUDA_HOME/nvcc --version` is 11.X
# export CUDA_HOME=/usr/local/cuda-11.1
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=${CONDA_PREFIX}/include" --install-option="--blas=openblas"
# Or if you want local MinkowskiEngine
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
系统 Python¶
与 anaconda 安装一样,确保您使用 nvcc 使用的相同 CUDA 版本安装 pytorch。
# install system requirements
sudo apt install build-essential python3-dev libopenblas-dev
# Skip if you already have pip installed on your python3
curl https://bootstrap.pypa.io/get-pip.py | python3
# Get pip and install python requirements
python3 -m pip install torch numpy ninja
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
python setup.py install
# To specify blas, CXX, CUDA_HOME and force CUDA installation, use the following command
# export CXX=c++; export CUDA_HOME=/usr/local/cuda-11.1; python setup.py install --blas=openblas --force_cuda
快速开始¶
要使用 Minkowski Engine,您首先需要导入引擎。然后,您需要定义网络。如果您拥有的数据未量化,则需要将(空间)数据体素化或量化为稀疏张量。幸运的是,Minkowski Engine 提供了量化函数 (MinkowskiEngine.utils.sparse_quantize)。
创建网络¶
import torch.nn as nn
import MinkowskiEngine as ME
class ExampleNetwork(ME.MinkowskiNetwork):
def __init__(self, in_feat, out_feat, D):
super(ExampleNetwork, self).__init__(D)
self.conv1 = nn.Sequential(
ME.MinkowskiConvolution(
in_channels=in_feat,
out_channels=64,
kernel_size=3,
stride=2,
dilation=1,
has_bias=False,
dimension=D),
ME.MinkowskiBatchNorm(64),
ME.MinkowskiReLU())
self.conv2 = nn.Sequential(
ME.MinkowskiConvolution(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=2,
dimension=D),
ME.MinkowskiBatchNorm(128),
ME.MinkowskiReLU())
self.pooling = ME.MinkowskiGlobalPooling()
self.linear = ME.MinkowskiLinear(128, out_feat)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.pooling(out)
return self.linear(out)
使用自定义网络进行前向和后向传播¶
# loss and network
criterion = nn.CrossEntropyLoss()
net = ExampleNetwork(in_feat=3, out_feat=5, D=2)
print(net)
# a data loader must return a tuple of coords, features, and labels.
coords, feat, label = data_loader()
input = ME.SparseTensor(feat, coords=coords)
# Forward
output = net(input)
# Loss
loss = criterion(output.F, label)
讨论和文档¶
如需讨论和提问,请使用 minkowskiengine@googlegroups.com。有关 API 和一般用法,请参阅MinkowskiEngine 文档页面以获取更多详细信息。
对于 API 上未列出的问题和功能请求,请随时在github 问题页面上提交问题。
已知问题¶
GPU 内存使用过多或频繁出现内存不足错误¶
此错误有几个可能的原因。
长时间训练期间内存不足
MinkowskiEngine 是一个专门的库,可以处理训练期间每次迭代不同数量的点或不同数量的非零元素,这在点云数据中很常见。然而,pytorch 的实现假设点的数量或激活的大小在每次迭代中不会改变。因此,pytorch 使用的 GPU 内存缓存可能导致不必要的巨大内存消耗。
具体来说,pytorch 缓存内存空间的块,以加速每次创建张量时使用的分配。如果它找不到内存空间,它会分割现有的缓存内存,如果缓存内存不够大,则分配新的空间。因此,每次我们使用不同数量的点(非零元素的数量)与 pytorch 时,它要么分割现有缓存,要么保留新的内存。如果缓存过于碎片化并分配了所有 GPU 空间,则会引发内存不足错误。
为防止这种情况,您必须定期使用 torch.cuda.empty_cache() 清除缓存。
CUDA 11.1 安装¶
wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
sudo sh cuda_11.1.1_455.32.00_linux.run --toolkit --silent --override
# Install MinkowskiEngine with CUDA 11.1
export CUDA_HOME=/usr/local/cuda-11.1; pip install MinkowskiEngine -v --no-deps
在具有大量 CPU 的节点上运行 MinkowskiEngine¶
MinkowskiEngine 使用 OpenMP 来并行化内核映射生成。 但是,当用于并行化的线程数太大时(例如 OMP_NUM_THREADS=80),效率会迅速下降,因为所有线程都只是等待多线程锁释放。 在这种情况下,设置用于 OpenMP 的线程数。 通常,低于 24 的任何数字都可以,但在您的系统上搜索最佳设置。
export OMP_NUM_THREADS=<number of threads to use>; python <your_program.py>
引用 Minkowski Engine¶
如果您使用 Minkowski Engine,请引用
@inproceedings{choy20194d,
title={4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks},
author={Choy, Christopher and Gwak, JunYoung and Savarese, Silvio},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={3075--3084},
year={2019}
}
对于多线程内核映射生成,请引用
@inproceedings{choy2019fully,
title={Fully Convolutional Geometric Features},
author={Choy, Christopher and Park, Jaesik and Koltun, Vladlen},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={8958--8966},
year={2019}
}
对于高维卷积的步长池化层,请引用
@inproceedings{choy2020high,
title={High-dimensional Convolutional Networks for Geometric Pattern Recognition},
author={Choy, Christopher and Lee, Junha and Ranftl, Rene and Park, Jaesik and Koltun, Vladlen},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}
对于生成式转置卷积,请引用
@inproceedings{gwak2020gsdn,
title={Generative Sparse Detection Networks for 3D Single-shot Object Detection},
author={Gwak, JunYoung and Choy, Christopher B and Savarese, Silvio},
booktitle={European conference on computer vision},
year={2020}
}
单元测试¶
对于单元测试和梯度检查,请使用 torch >= 1.7
使用 Minkowski Engine 的项目¶
请随时更新 wiki 页面 以添加您的项目!
表征学习: 全卷积几何特征, ICCV’19
3D 注册: 学习多视角 3D 点云注册, CVPR’20
3D 注册: 深度全局注册, CVPR’20
模式识别: 用于几何模式识别的高维卷积网络, CVPR’20
图像匹配: 稀疏邻域一致性网络, ECCV’20
